
Data Lake
Data Lake
A data lakehouse is a modern, open architecture that enables you to store, understand, and analyze all your data. It combines the power and richness of data warehouses with the breadth and flexibility of the most popular open source data lake technologies. You can use a data lakehouse on Oracle Cloud Infrastructure (OCI) to work with the latest AI frameworks and prebuilt AI services.
Content Detail
Dropdown link
Oracle Data Lake
Oracle Data Lake
Product Description
A data lake is a scalable, centralized repository that can store raw data and enables an enterprise to store all its data in a cost effective, elastic environment. A data lake provides a flexible storage mechanism for storing raw data. For a data lake to be effective, an organization must examine its specific governance needs, workflows, and tools. Building around these core elements creates a powerful data lake that seamlessly integrates into existing architectures and easily connects data to users.
Product IMAGE
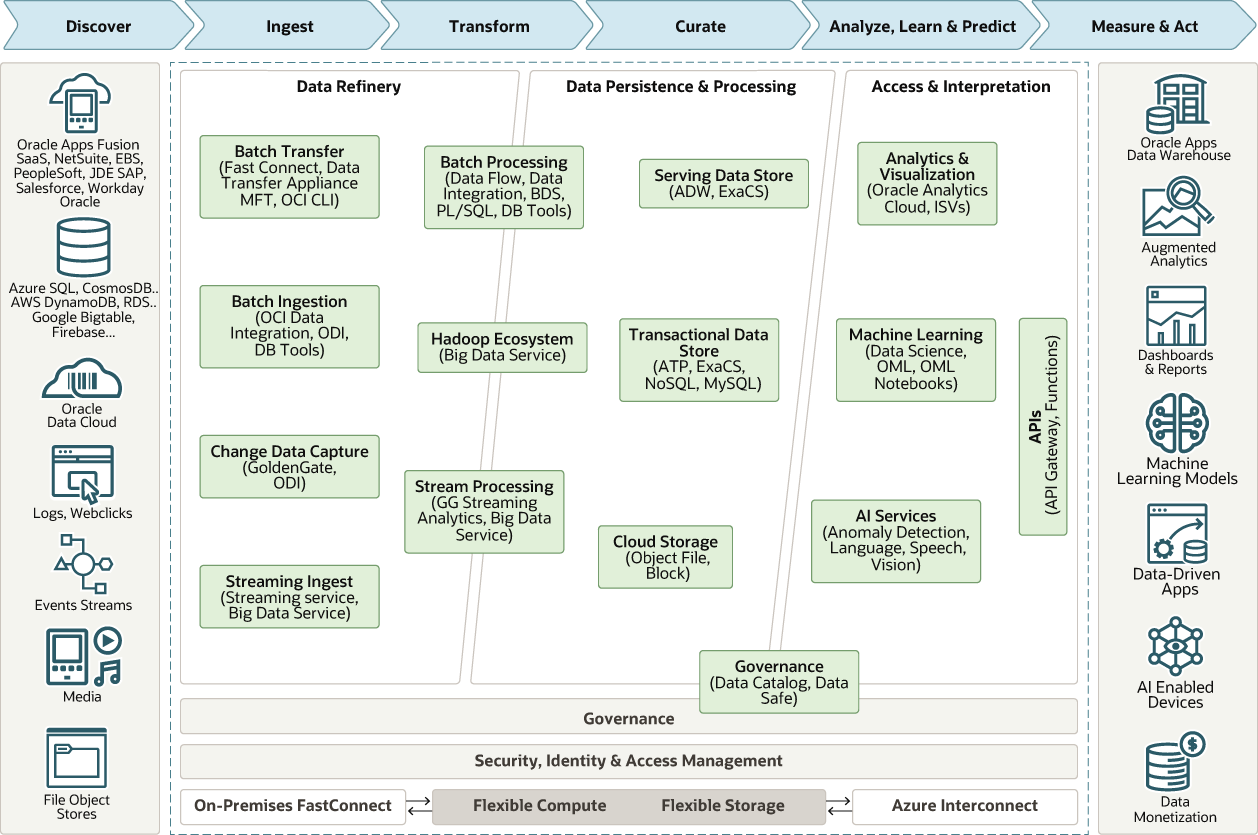
Product FEAtures
To make unstructured data stored in a data lake useful, you must process and prepare it for analysis. This is often challenging if you lack extensive data engineering resources.
The following lists the technical challenges of maintaining on-premises data lakes.
- Upfront costs and lack of flexibility: When organizations build their own on-premises infrastructure, they must plan, procure, and manage the hardware infrastructure, spin up servers, and also deal with outages and downtime.
- Ongoing maintenance costs: When operating an on-premises data lake, mostly manifesting in IT and engineering costs, organizations must account for ongoing maintenance costs. This also includes the costs of patching, maintaining, upgrading, and supporting the underlying hardware and software infrastructure.
- Lack of agility and administrative tasks: IT organizations must provision resources, handle uneven workloads at a large scale, and keep up with the pace of rapidly changing, community-driven, open-source software innovation.
- Complexity of building data pipelines: Data engineers must deal with the complexity of integrating a wide range of tools to ingest, organize, preprocess, orchestrate batch ETL jobs, and query the data stored in the lake.
- Scalability and suboptimal resource utilization: As your user base grows, your organization must manually manage resource utilization and create additional servers to scale up on demand. Most on-premises deployments of Hadoop and Spark directly tie the compute and storage resources to the same servers creating an inflexible model.
The following lists the business benefits of moving your data lakes to the cloud.
- Lower engineering costs and managed services: Build preintegrated data pipelines more efficiently with cloud-based tools and reduce data engineering costs. Transfer scaling management to your cloud provider using cloud services such as Object Storage and Autonomous Data Warehouse (ADW) that provide transparent scaling. You don't need to add machines or manage clusters on cloud-based data lakes.
- Leverage Agile infrastructure and latest technologies: Design your data lake for new use cases with our flexible, agile, and on-demand cloud infrastructure. You can quickly upgrade to the latest technology and add new cloud services as they become available, without redesigning your architecture.
Link Document